













Identity Confluence - An Innovative IGA Platform
An IGA platform that truly ensures compliance across enterprise systems.
Automated User Provisioning and Deprovisioning.
Seamless Integration with Identity Platforms and HR Platforms for Identity Sync.
Policy-Based Access Control (PBAC) for Org. level Policy enforcement.
Real-time Identity Reconciliation with IdP for Org. level Compliance.
RBAC for automated and compliance driven access management.
Comprehensive Reporting and Dashboards for Audit Compliance.
Data Confluence - Data to Dashboard Platform
Databricks powered Data platform which brings clarity to complex data with precision and speed.
Data Ingestion, Processing, Transformation, and Analytics.
Visual Data Pipeline Builder through an intuitive user interface.
100+ Data Connectors for seamless Enterprise Integration.
Packaged libraries for Data Transformation and Data conversion
MLOps and GenAI Integration to support on-demand data insights.
Comprehensive reports and dashboards within the familiarity of your BI tool.
Our Software Services
Our Services help customers accelerate their product development journey and release cycles.






Product Engineering
Product engineering is our DNA and with relentless obsession with the quality of our deliverables, we build lasting partnerships with our customers as we turn their ideas into reality by delivering innovative software solutions that drive business growth
Powering breakthrough success
Our customers are innovating faster and achieving accelerated outcomes while still reducing their cost.












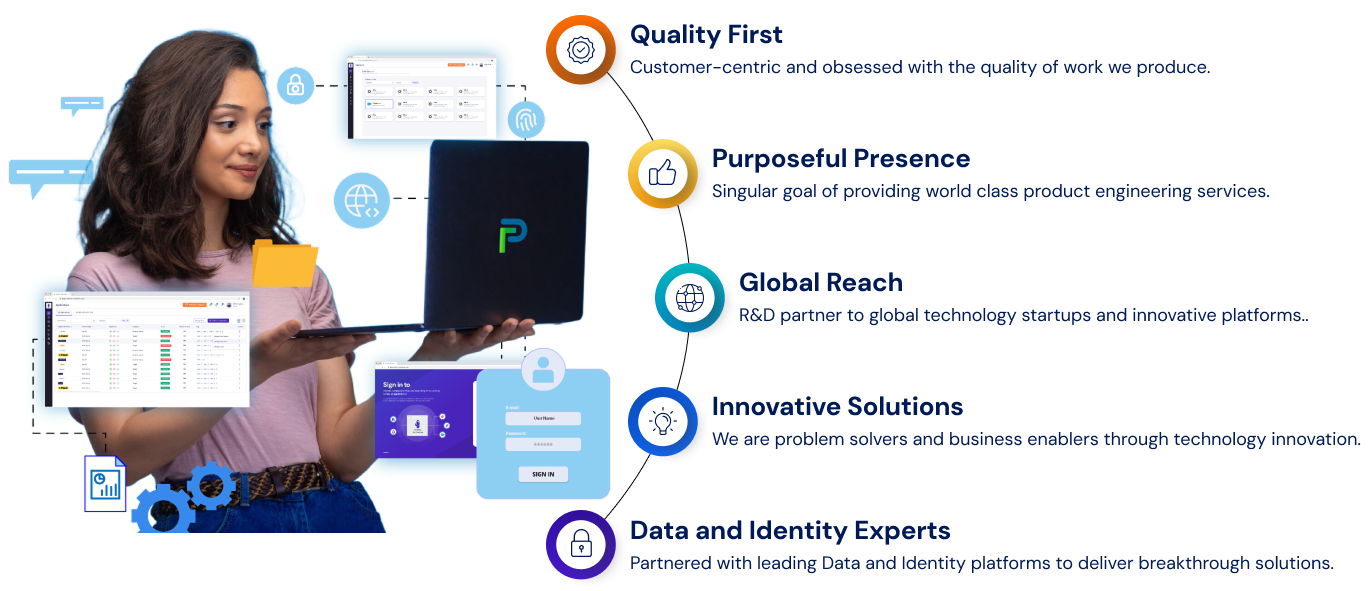
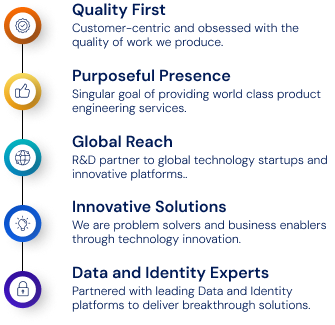
Why Tech Prescient?
We Deliver Awesome and Delightful Customer Experiences!

What Our Customers Say
Real experiences, real impact. See how we’ve helped customers thrive with tailored services.


Tech Prescient was very easy to work with and was always proactive in their response.
The team was technically capable, well rounded, nimble and agile. They could interpret, adopt and implement the required changes quickly.

MURALI RAMSUNDER
SENIOR ARCHITECT, VONAGE.COM


Amit and his team at Tech Prescient have been a fantastic partner to Measured.
We have been working with Tech Prescient for over three years now and they have aligned to our in-house India development efforts in a complementary way to accelerate our product road map.

TREVOR TESTWUIDE
CO-FOUNDER & CEO, MEASURED INC.

We were lucky to have Amit and his team at Tech Prescient build CeeTOC platform from grounds-up.
Having worked with several other services companies in the past, the difference was stark and evident.

ALOK SRIVASTAVA, PHD
FOUNDER AND CEO, CEETOC INC.

We have been extremely fortunate to work closely with Amit and his team at Tech Prescient.
The team will do whatever it takes to get the job done and still deliver a solid product with utmost attention to details.

SREENIVASA GORTI, PHD
CTO / CO-FOUNDER, INNOSTREAMS INC.
Trusted By The Industry’s Best Organizations




Tech Prescient Blogs
Explore the best practices and perspectives shared by our technology experts.





